Grok Imagine v1.0 vs v0.9: The 17-Second Generation Barrier
> v0.9 proved xAI could ship sub-15s video. v1.0 cut wall-clock time to roughly 17 seconds for a finished 720p clip and pushed duration to 10 seconds with synced audio. Here is what actually changed.
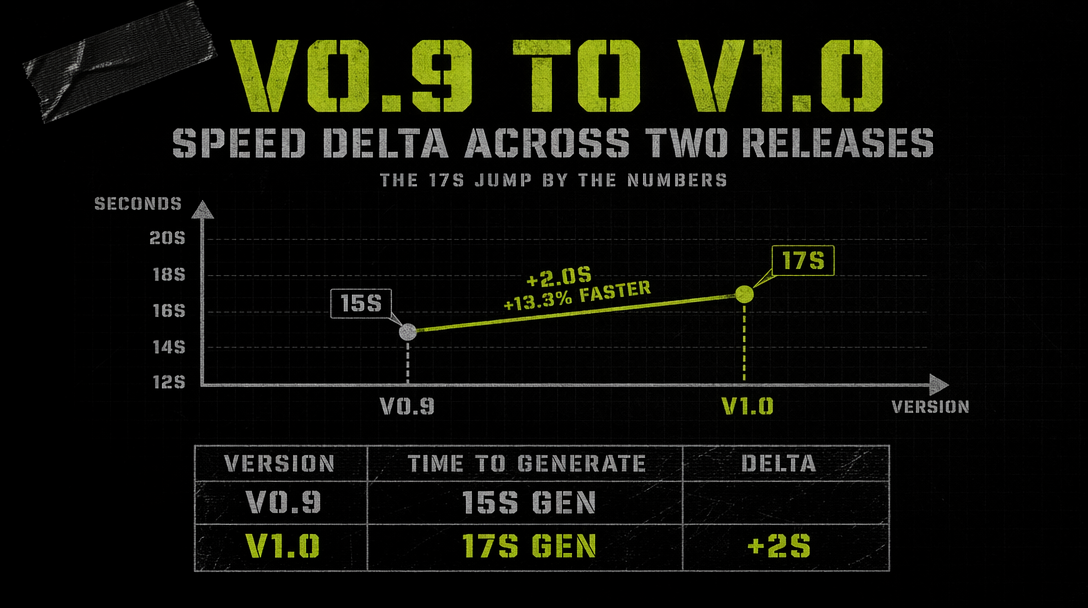
When xAI dropped Grok Imagine v0.9 on October 5, 2025, the headline was raw speed. The model put a 6-second clip with native audio on your screen in under 15 seconds of wall time. That number was already faster than anything else in the arena. Four months later v1.0 landed on February 1-2, 2026, and the whole proposition shifted. You now get a 10-second clip at 720p, audio that actually tracks lip movement, and prompt adherence that no longer wanders off halfway through the shot.
This post walks through what changed in v1.0, why the speed edge still holds even with a longer max duration, and where the v0.9 habits you had break.
What v0.9 was good at
v0.9 was the first text to video model that treated generation time as a product feature. The pitch was simple. You type a prompt, you wait roughly the length of a coffee sip, and you have a clip with synchronized audio. Duration capped at 6 seconds, resolution at 720p, and the audio channel was muddy but present. Motion was sometimes soft, hands warped in close shots, but the iteration speed meant you could try ten prompts in the time a competing model produced one.
What shipped on February 1-2
v1.0 landed with five concrete changes you care about.
Duration moved from 6 to 10 seconds. The default is still 6 when you leave the parameter empty, but you can ask for up to 10 in a single call. Past 10 you hit the hard 15-second ceiling through the extend from frame feature.
Audio got a real upgrade. v0.9 audio tracked scene mood. v1.0 audio tracks phonemes. Lip sync lands correctly on the first or second try for short dialogue.
Prompt adherence tightened. v0.9 would often miss secondary details once a prompt passed around 40 words. v1.0 holds onto specifics like wardrobe, camera movement, and lighting direction across the full 10 seconds. The LM Arena T2V board puts v1.0 at Elo 1232, ranked fifth. I2V sits at 1325, ranked third.
Image generation got reworked. The sibling endpoint xai/grok-imagine-image now handles 1k and 2k outputs with up to four images per call.
Generation time stayed roughly flat. v0.9 averaged 12 to 14 seconds for a 6-second clip. v1.0 averages 15 to 19 seconds for a 10-second 720p clip with audio.
Running v1.0 through the fal client
1import { fal } from "@fal-ai/client";23fal.config({ credentials: process.env.FAL_KEY });45const result = await fal.subscribe("xai/grok-imagine-video/text-to-video", {6 input: {7 prompt: "A street vendor flips a chestnut skillet at dusk, steam rising, city lights blurring behind him, handheld documentary style",8 resolution: "720p",9 duration: 10,10 audio: true,11 aspect_ratio: "16:9"12 },13 logs: true14});1516console.log(result.data.video.url);
The call returns in roughly 17 seconds for a 10-second 720p clip with audio. Cost for that output lands at $0.70 (10 seconds at $0.07 per second). A 480p variant drops to $0.50 for the same duration.
Where v0.9 habits break
If you were batching v0.9 jobs around a 6-second assumption, your prompts are probably too compressed for v1.0. The model rewards more descriptive prompts now, so the ten-word prompts that worked before will produce clips with dead time at the back half.
Audio prompts matter. v0.9 would sometimes produce clean ambient tracks even without audio instructions. v1.0 follows audio cues literally. If you want speech, write speech. If you want a quiet scene, say so.
The 15-second hard cap is still there. v1.0 stretches to 10 seconds natively, and extend from frame pushes you to 15. For longer shots, you chain clips.
When the speed still matters
Seventeen seconds sounds mundane until you put it next to competing models that take 45 to 90 seconds for equivalent output. The speed edge compounds during iteration. You can try six variations of a shot in the time a slower model produces one, which changes how you approach prompting. You sketch rather than commit.
That is the 17-second barrier. Not a limit, a new reference point for what text to video feels like when the round trip is short enough to keep you in flow.